Birthday hashing
A hash table is a commonly used data structure in computer science. It is one of the most useful data structures because of its speed in information retrieval. For example, suppose we want to store peoples' addresses. For each person we are tasked to store their name as the key and home address as the value. With proper notation, if $x$ is the name of a person then $h(x)$ is the index at which the home address can be found (if the hash table is implemented using an array). Nothing too special, just a function.
However, problems arise if by chance two people have the same name or hash to the same index (so $x=y$ causes $h(x)=h(y)$). Trouble starts when we attempt to store more than one "item" in the same "slot". The efficiency of all hashing algorithms depends on how often this happens. There are two common ways of hashing, either linear probing or chaining using linked lists. When using an array of linked lists, once we want to recall a person's address, we hash their name (apply $h$ to $x$) to get the index in the hash table and if there are multiple names that hash to the same key, we have to check each one of them until we find the right one, traversing the linked lists from left to right giving $\mathcal{O}(\ell)$ where $\ell$ is the length of the linked list. This is called a collision. Here is a really, really good video explaining the difference between linear probing and chaining: Hash Tables and Hash Functions
The hash function $h$ is deterministic. Every time you look up the index of a name you get the same thing back each time.

To showcase the problem with hashing, I'll start with a very similar problem. I mentioned it in a previous post here: Expected values. The question is simple (assume no person is born on February 29th):
Birthday paradox
In a set of $23$ people the probability that two share the same birthday is greater than $0.5$ (or $50$%).
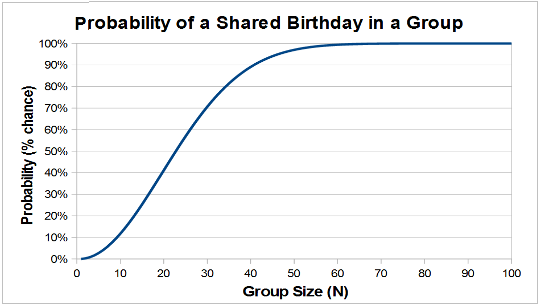
Back to hashing
The basic mechanism in hashing is the same as in the assignment of birthdays. We have $n$ items and map each to one of $k$ slots. We assume the $n$ choices of slots are independent. A collision is the event that an item is mapped to a slot that already stores an item. A possible resolution of a collision adds the item at the end of a linked list that belongs to the slot. Now I'll discuss some expected values of different situations in hashes.Here's a very cool paper showcasing the methods used in digital forensics for creating attacks in digital evidence: A review of collisions in cryptographic hash function used in digital forensic tools
E.V. of number of items in same slot
In a set of $n$ people and $k$ slots available, the expected number of items per slot is $n/k$.
Solution
We can assume without loss of generality that we are focusing on the first slot. Let $T_i$ be $1$ if the $i$-th item is mapped to the first slot, and $0$ otherwise. The expected value of the $\textnormal{r.v.}$ $T_i$ is $1/k$ obviously, therefore the expected value of the number of items mapped to the first slot is: \[ \mathbb{E}[T] = \sum \limits_{i=1}^{n} \mathbb{E}[T_i] = n/k \]
E.V. of number of empty slots
In a set of $n$ people and $k$ slots available, the expected number of empty slots is $k (1- \frac 1k)^n$.
Solution
Let $T_i$ be the indicator variable that is $1$ if slot $i$ is empty and $0$ otherwise. It is clear that $\mathbb{E}[T_i] = (1-\frac 1k)^n$ hence the expected value of the number of empty slots in total is by summing over $k$ slots: \[ \mathbb{E}[\textnormal{# of empty slots}] = k (1- \frac 1k)^n \] Especially interesting is that if $k=n$ then by randomly assigning items to slots the expected number of empty slots is about $36$% since $(1-\frac{1}{n})^n = 1/e$ in the limit.
E.V. of collisions
In a set of $n$ people and $k$ slots available, the expected number of collisions is $n-k+k (1- \frac 1k)^n$
Solution
This can be inferred from the number of empty slots. If $A$ is the number of empty slots, we have $k-A$ items hashed without collision and hence $n-k+A$ collisions. You can think of the first time that an item lands on a slot that doesn't end up being free. It contributes $1$, $k-A$ times. Taking the expected value of this we get: \[ \mathbb{E}[\textnormal{# of collisions}] = n-k+k (1- \frac 1k)^n \]
E.V. of the number of needed items to fill all slots
Given $k$ slots, the expected number of items needed to map to these slots is $k H_k$ where $H_k$ is the $k$-th harmonic number
Solution
The $k$-th harmonic number is just: $H_k = 1+\frac 12 + \frac 13 + \ldots + \frac 1k$.This is trickier than the last examples because it involves a different kind of indicator variable.
Let $T$ be the number of draws needed in average to fill the slots. Let $T_i$ be the expected number of items to go from having $i$ slots filled to $i+1$ slots filled. Notice that this is not the same for different $i$. It is much easier to get from $1$ item filled to $2$ than from $k-1$ to $k$. This is exactly the intuition behind the solution. The probability of filling a new slot is: \[ \mathbb{P} = \frac{k-i+1}{k}\] hence our random variable has expected value: $\frac{k}{k-i+1}$ since it has geometric distribution. This is also the same logic behind the Mean Time to Failure from the post Unexpected expected values. You have an event with probability $p = \frac{k-i+1}{k}$ of occuring each time you "try". The expected value of the number of tries is $1/p = \frac{k}{k-i+1}$. With a computer crashing with probability $p$ each time you turn it on, you would expect to turn it on $1/p$ times and have it crash once. Another example is calculating the expected number of die rolls before landing a $6$.
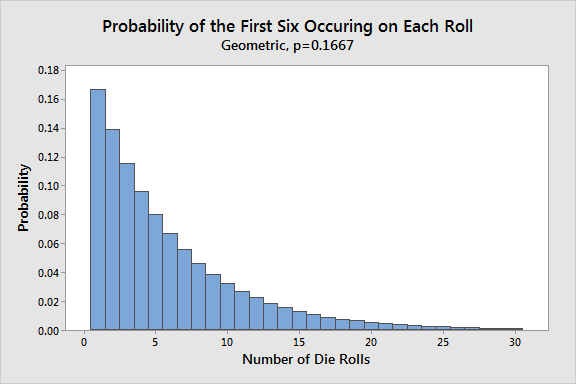
Now by the Linearity of Expectations we conclude: These examples show the mathematics behind hashing and why we should care about collisions.
Interesting Hash Table Problems
- Problem 1 (Oxford Problem Sheet Question)
- Each bucket in a hash table represents a mapping from certain keys (all those that have a certain hash code) to values. In our implementation of hash tables, each bucket is represented as an unordered linked list, with a time for lookup of $O(N)$, where $N$ is the length of the list. Wouldn’t it be a good idea to replace these linked lists with some other data structure that represents a mapping with better asymptotic complexity?
- Problem 2 (Oxford Problem Sheet Question)
- Suppose a hash table with $N$ buckets is filled with $n$ items, and assume that the values of the hash function for the $n$ items are independent random variables uniformly distributed in $\text{[0..N)}$. What is the probability distribution for the number of items that fall in a particular bucket? What is the expected number of comparisons of keys that are performed when get is called and the search is (a) successful and (b) unsuccessful?
References and links for further reading
- Duke University Lecture 18 Probability in Hashing
- A review of collisions in cryptographic hash function used in digital forensic tools
- Introduction to Probability, Prof. Dennis Sun
- Evan Chen's Probabilistic method
- Harvard, Prof. Joe Blitzstein, Stat 110
- "How Many Cycles Will You Find in a Random Permutation?" by Haris Angelidakis
- MIT OCW - Expectation: Chapter 18.4-18.5